🚀 Breaking Down the Monolith: A Quick Guide to Data Migration Patterns
In a previous post, I shared some application migration patterns from Sam Newman’s Monolith to Microservices book. The author also delves into crucial database migration patterns, which are fundamental for fully decoupling a monolith. In this post, I’ll provide a concise overview of these database migration patterns. For anyone planning or managing a transition to microservices, I highly recommend this book—it’s an excellent read for practical insights!
Here’s a summary of my understanding of these key patterns:
Fundamental Patterns:
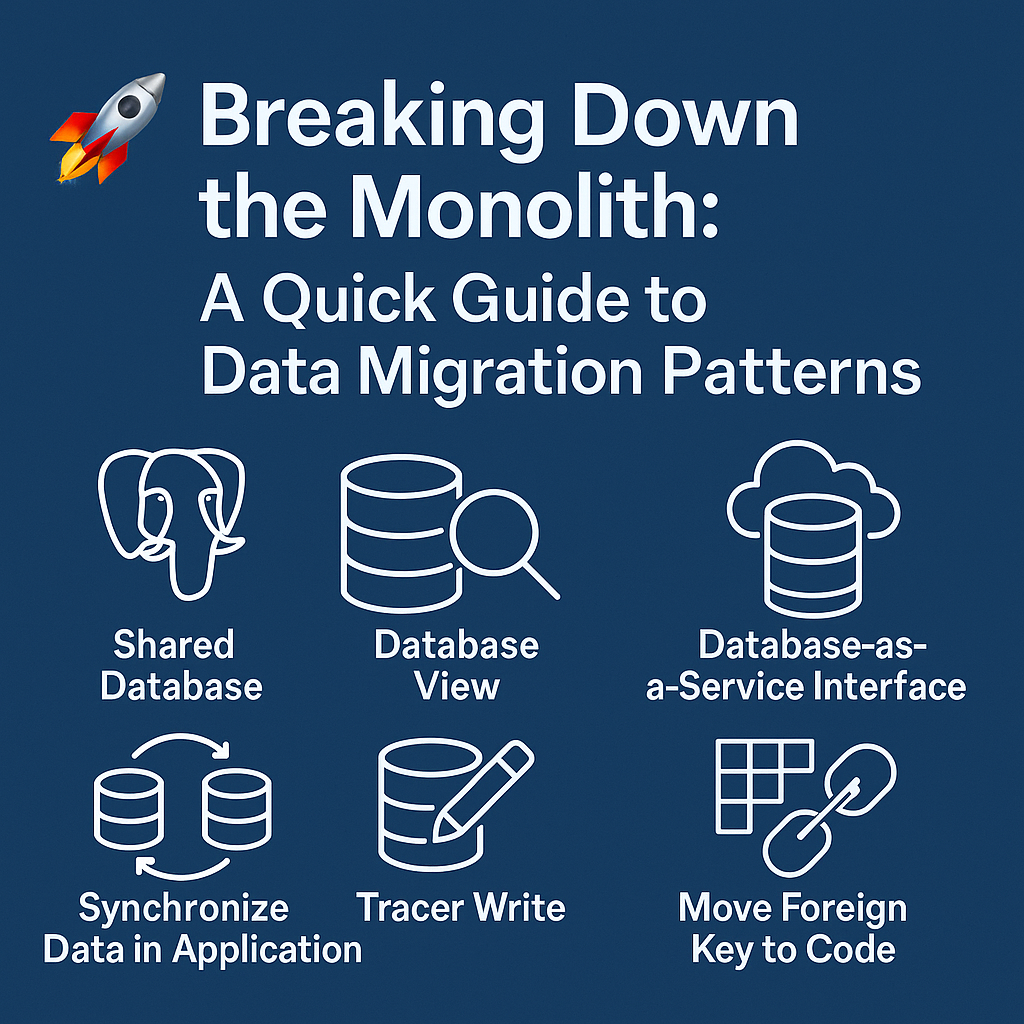
1. Shared Database 🐘
🚫 Anti-pattern Alert! A shared database creates tight coupling and limits service independence. Though sometimes necessary at the start, the goal is to shift away from this model to enable scalability and clearer data ownership.
2. Database View 🔍
Views provide limited, read-only access to specific fields when complete schema separation isn’t feasible. For instance, a “customer view” could restrict each service’s access to only essential data, while the underlying schema remains shared.
3. Database Wrapping Service 🎁
This pattern hides the database behind a service interface, letting internal schema changes happen without impacting other services—helpful for legacy systems with business logic embedded in stored procedures.
4. Database-as-a-Service Interface ☁️
This pattern suggests offering a read-only database endpoint for analytics or reporting, separate from the transactional database. For example, an Orders service could utilize a read-only database for analytics to reduce load on its main system.
Data Synchronization Strategies:
1. Synchronize Data in Application 🔄
For critical migrations, this pattern writes to both the old and new databases simultaneously, ensuring that they remain in sync to maintain data consistency. Useful for data-sensitive migrations like medical applications, though it requires strong consistency and error management.
2. Tracer Write ✍️
Gradually shifts the source of truth by duplicating writes across both systems, making it less disruptive than an all-at-once migration. This works well for staged migrations, such as incrementally migrating invoice data.
Schema Refactoring:
1. Split Table ✂️
Splits large, shared tables that span multiple domains into separate tables, each belonging to specific services. For example, product and inventory data might be separated to support individual service ownership.
2. Move Foreign Key to Code 🔗
Manages foreign key relationships that span service boundaries within the application, rather than in the database, to maintain data integrity as services are split apart.
Together with application migration patterns, these approaches form a powerful toolkit for decomposing monoliths into microservices. A structured, phased approach to data migration is key to making this transition smoothly!
Feel free to share your thoughts on this LinkedIn post.